3D Cross-Hair Convolutional Neural Networks
+ Holographic Medical Imagining Devices + Volumetric Video Rendering + Brain Machine Interfaces (NerveGear) + Deep Learning Artificial…

+ Holographic Medical Imagining Devices + Volumetric Video Rendering + Brain Machine Interfaces (NerveGear) + Deep Learning Artificial Intelligence.
The Neural Lace Journal by Micah Blumberg, Journalist, Researcher, Neurohaxor at http://vrma.io
One of the first steps to accomplish Neural Gear, Neural Lace, or the next generation Brain Machine Interface is that we need to correlate 3D volumes of data from the real world, such as data that an autonomous vehicle might capture, with 3D volumes of data from medical imaging, such as the holographic data that might be captured by Mary Lou Jepsen’s Holographic Near Infrared Medical Imagining device called Openwater (I’m hoping to get a dev kit) that I mentioned previously here:
3 New Medical Imagining Technologies that have Neuroscientists salivating like Pavlov’s dogs.
These three exciting new medical scanning technologies have neuroscientists dreaming about the prospects of next generation of medical…medium.com
To get there not only do we need advances in Volumetric Data capture, rendering, and streaming. Reference: OTOY and the work of Jules Urbach.
My interview with Jules Urbach the CEO of OTOY at GTC 2018
We talked about some of the big ideas behind the big news about RTX Real Time Ray Tracing, we talked specifically about AI Lighting, AI…medium.com
Join the Volumetric Video group here https://www.facebook.com/groups/volumetric/
Volumetric Video VR AR Professionals: Point Cloud, 3D Mesh, Holograms
Volumetric Video VR AR Professionals is for Professionals who want to capture holograms of rooms or create 3D video that…www.facebook.com
We also need advances in basic brain machine interfaces such as in how to read and write to the brain.
Neural Lace and Deep Learning
Meet Polina Anikeeva, Associate Professor of Materials Science and Engineering at Massachusetts Institute of Technology, and an important…medium.com
On top of that we need innovations in Deep Learning Artificial Neural Networks to identify and segment brain activity that directly correlates to patterns in the real world that have been captured and streamed by robots (autonomous vehicles)
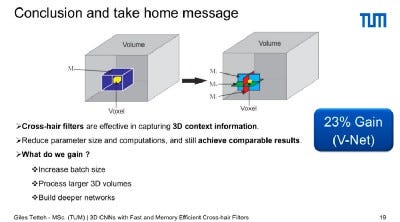
The conclusion from a new paper presented at Nvidia’s GPU Technology Conference GTC 2018 is that 3D Convolutional Neural Network Cross Hair Filters are effective for use with 3D volumes of data and you get an immediate 23% gain in memory that will allow you to do things like increase your batch size, process larger 3D volumes, build deeper networks, or run at the same level of performance on cheaper hardware.
A 23% gain in the depth of the network could be significant for example because the trend in computer vision, via ImageNet, is that top error rates have been decreasing inversely to the depth of the network
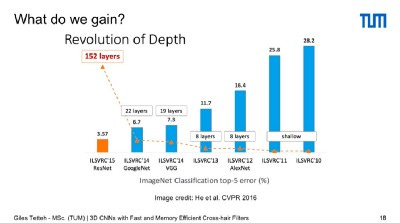
The paper the talk was based on is titled “3D CNNS with Fast and Memory efficient Cross-hair Filters” was submitted to GTC by Giles Tetteh, a PhD Candidate from the Image Based Biomedical Group, Graduate School of Bioengineering, Techniskche Universität München
The Image-Based Biomedical Modeling group led by Prof. Menze works on extracting information from medical images. From image acquisition (MRI / CT/ PET) to Structuring Visual Information (detection and segmentation) to empirical correlations and diagnostic to functional models (for diseases). Convolutional Neural Networks are used to do detection and segmentation of objects in the 3D volume of medical data.
When you first learn about Convolutional Neural Networks, they are used to classify 2D images, an example is the Hotdog / Not Hotdog app featured on the hit tv show Silicon Valley.
Originally, before Hotdog no hotdog it was Cat vs Dog, can your CNN detect whether its looking at a cat verses a dog? That’s classification.
After that we had classication with localization, and then object detection, that we could see with Nvidia Driveworks in 2016
An article about Deep Learning that I wrote in 2016
Deep Learning Fuels Nvidia: Self-Driving Car Technology
Deep Learning Fuels Nvidia: Self-Driving Car Technology Posted at Radical Science News on January 27, 2016 by Adam…vrmadotwork.wordpress.com
More recently advances have allowed Convolutional Neural Networks to do semantic segmentation which sort of means giving a label to each pixel or voxel or point in a pointcloud in an image or a volumetric video. So you can identify the actual spatial volume of a cat and make that distinct from a wall.
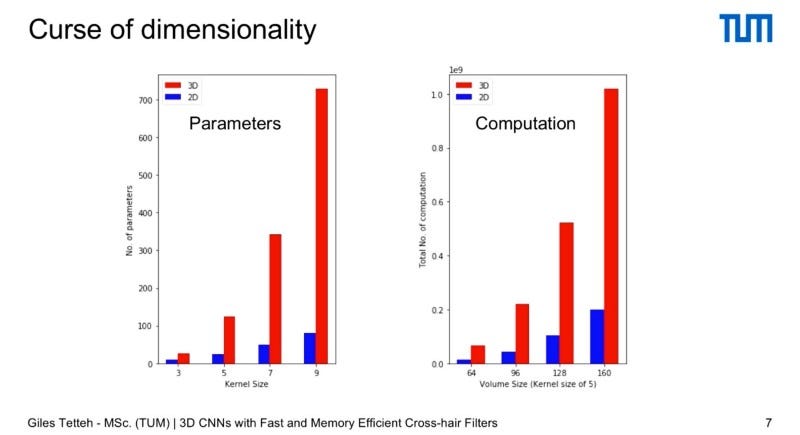
When you are dealing with self driving cars and medical imaging one of the biggest challenges is that spatial data from the real world is 3D. We often have three dimensional data and very large volumes of it.
If you try to use a 3D CNN with 3D data you are immediately going to see your memory consumed (parameters required) and computation price increase (processing more parameters takes more computation time and thus is increases your computational cost)
Currently the Medical Community and the Self Driving Car community have been experimenting with 2.5D networks, which means any combination of a 2D convolutional neural network with a 3D volume of image data.
That might mean running CNNs on 2D slices of 3D data into one 2D CNN and then use smart processing to put the slices together after.
The main setbacks of that approach is that there is still a lack of 3D contextual information and a lot of redundant computation ends up being done which is computationally expensive.
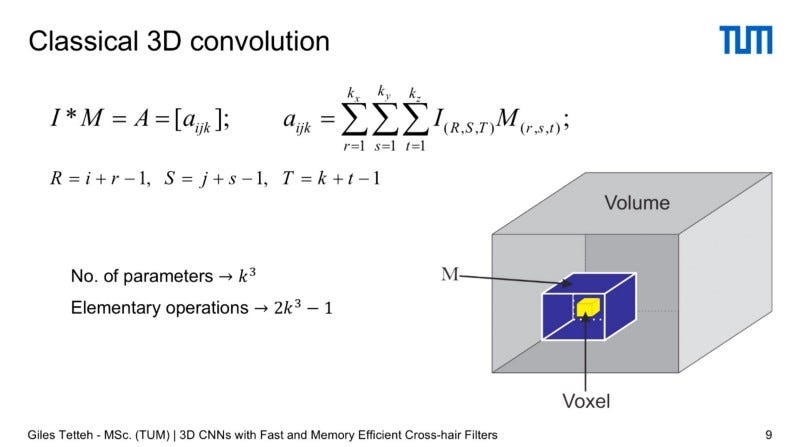
A Classical 3D Convolutional Neural Network (as explained by the proposal by Giles Tettech to replace 3D Convolutions with cross hair filter) allows you to define a volume of space, like a box, which you use as a 3D filter that you swipe through a 3D volume that represents your data, then you do a voxel wise multiplication of the weights of the filter with the image, then you assign the sum of all the weights of the multiplication of the image with the filter to the center voxel. So you have a 3D volume as an input and a 3D volume as an output. If you have an isotopic filter represented as linear size k then you need to define K to the third, and you have about 2 times K to the third parameters to do.
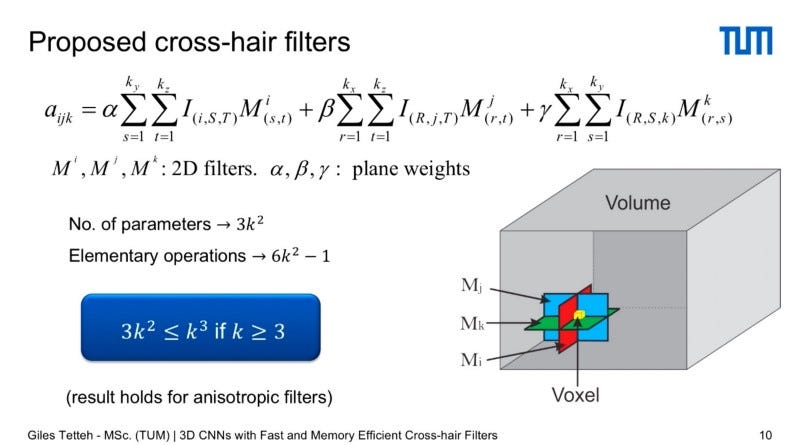
The New 3D Cross Hair Convolutional Neural Networks (as explained by The Proposal from Giles Tettech is to replace 3D Convolutions with cross-hair filters.) are different in that now you only need to define three 2D cross hair filters, each one is a plane that represents either an X, Y, or Z axis. Then you assign to the central voxel the sum of the result of the three convolutions, and then you can swipe that through the whole volume. You need to define the number of parameters as 3k to the second, and the number of elementary operations is about 6k to the second.
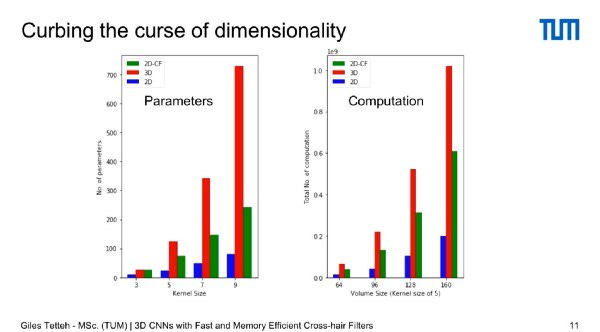
The result recovers quadratic scaling, reduces the number of parameters needed, recovering memory and reducing computation time.

To prove that it works first they tried it on MNIST which is a 2D data set and they noticed a twenty percent improvement in speed with an acceptable error rate proving that it can handle 2D planes. Cross Hair filters can catch most of the relevant information needed to classify two dimensional images.
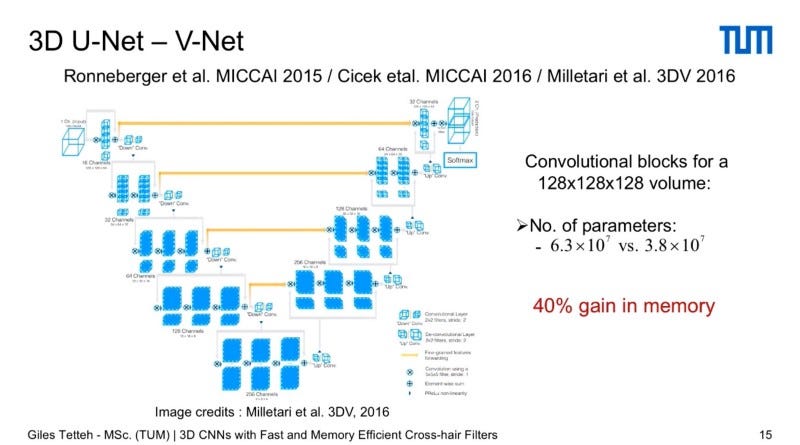
To test it’s performance on 3D data they used the 3D U-Net — V-Net which is the most used architecture for medical vision to do segmentation. It’s known as U-Net or V -Net because it has a down sampling pass and an upsampling pass which skip connections, and the point is that you have an output which is the exact same 3D volume size as the input. So if you replace the 3D convolutional blocks of this architecture for a volume of 128x128x128 then you end up reducing the number of parameters needed by 40 percent so you have basically a 40 percent gain in memory which is immediately significant.

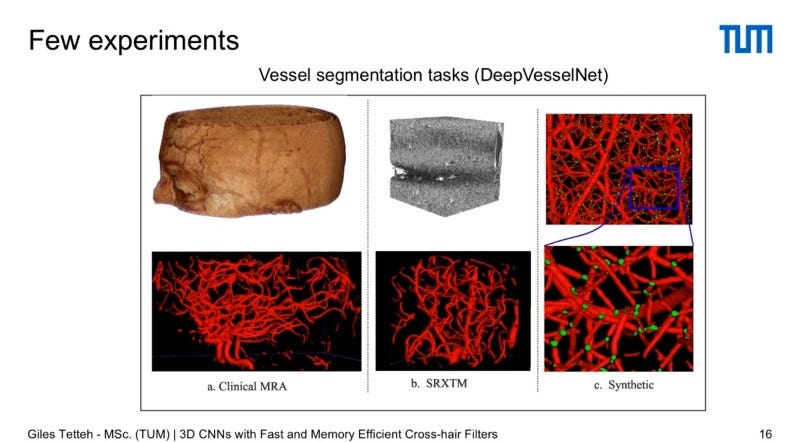
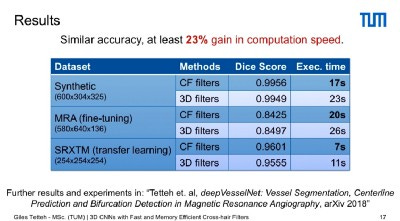
They further tested it on other data sets including MRI, SRXTM and a Synthetic Data set with very little loss in accuracy compared to 3D CNNS, but with a gain of at least 23% in computation speed thanks to Cross Hair filters.
Watch the full talk given at GTC 2018 here: http://on-demand.gputechconf.com/gtc/2018/video/S8318/
The talk was given by Marie Piraud — Senior Researcher, Technical University of Munich on behalf of Giles Tetteh (PhD Candidate from the Image Based Biomedical Group, Graduate School of Bioengineering, Techniskche Universität München)
“Over the years, state-of-the-art architectures have been built with convolutional layers and have been employed successfully on 2D image processing and classification tasks. This success naturally appeals for the extension of the 2D convolutional layers to 3D convolutional layers to handle higher dimensional tasks in the form of video and 3D volume processing. However, this extension comes with an exponential increase in the number of computations and parameters in each convolutional layer. Due to these problems, 2D convolutional layers are still widely used to handle 3D images, which suffer from 3D context information. In view of this, we’ll present a 3D fully convolutional neural network (FCNN) with 2D orthogonal cross-hair filters that makes use of 3D context information, avoiding the exponential scaling described above. By replacing 3D filters with 2D orthogonal cross-hair filters, we achieve over 20% improvement in execution time and 40% reduction in the overall number of parameters while accuracy is preserved.”
NVIDIA GTC 2018 - San Jose
on-demand.gputechconf.com
Thanks for reading.
Breaking News: Humans are metal robots literally.
Point 1: Your cells are filled with charged liquid metals, ie ions, positively charged sodium ions Na+ and negatively charged potassium K+…medium.com