
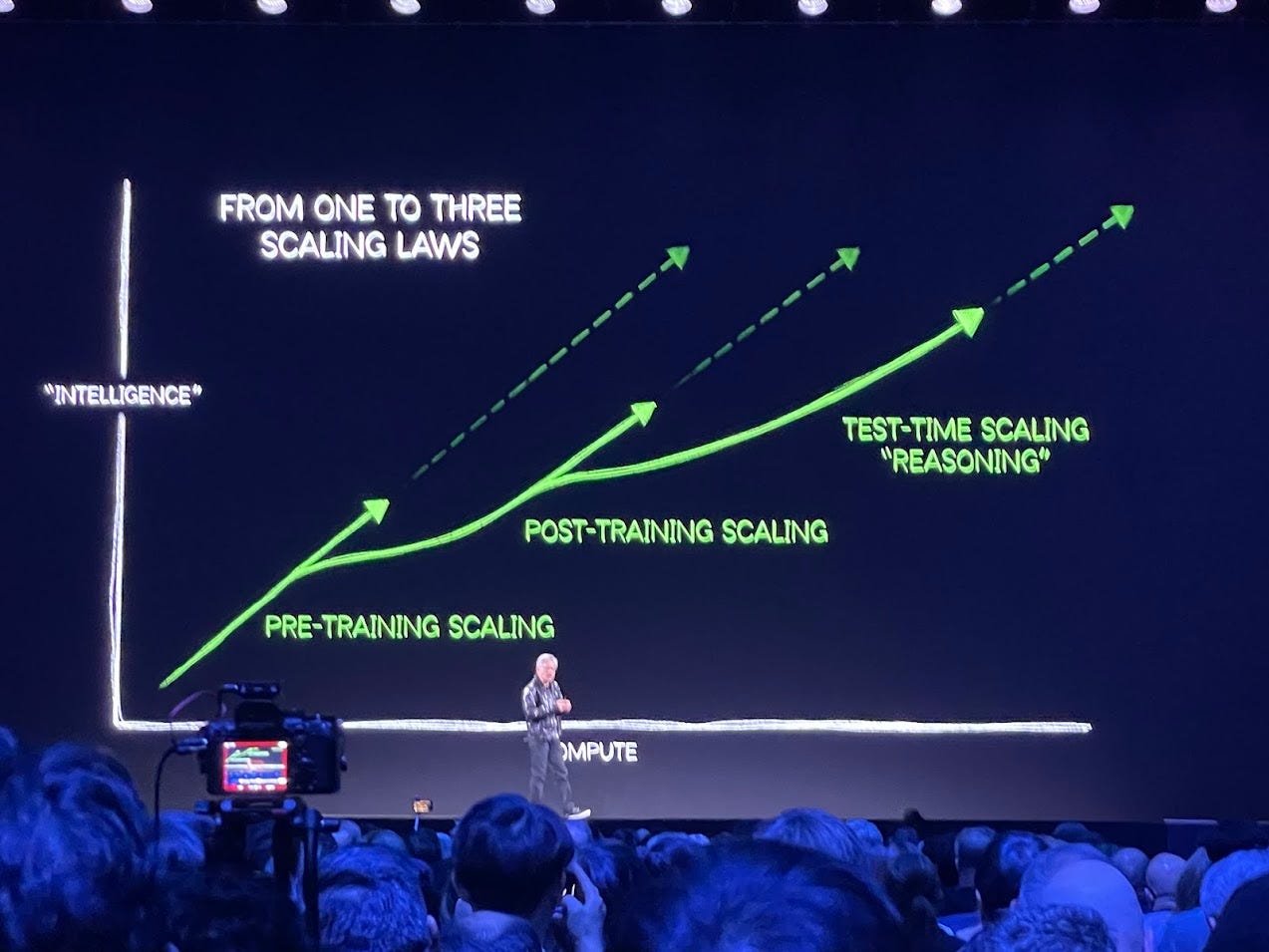
After the DeepSeek Shock: CES 2025’s ‘One to Three Scaling Laws’ and the Race for AI Dominance
Why Nvidia’s Stock Dip Missed the Real Story—Efficiency Breakthroughs Are Supercharging GPU Demand, Not Undercutting It.

It was a day of drama on Wall Street when shares of Nvidia plummeted by nearly 17 percent, slicing off around $600 billion from the chipmaker’s market cap. For a company that has long reigned as the go-to source of high-end graphics processing units (GPUs) in an age dominated by artificial intelligence, the tumble seemed to come out of nowhere. Likewise, competing chip designer AMD was down 6 percent, and TSMC—responsible for manufacturing many of Nvidia’s advanced chips—saw a 12 percent slide.
Almost immediately, the blame landed on DeepSeek, a Chinese AI lab whose latest models, V3 and R1, have been making waves for their jaw-dropping efficiency. On the surface, the narrative seemed to make sense: if DeepSeek’s breakthroughs allow “bigger brains” with fewer computational resources, the market might wonder whether high-powered GPUs would be rendered obsolete. But when you dig deeper, that line of reasoning starts to fall apart. If anything, most AI insiders believe DeepSeek’s achievements could increase the need for robust GPU power, not diminish it.
A Familiar Market Overreaction
What we’re seeing is a pattern as old as commerce itself: a major innovation emerges, investors misunderstand (or are misled about) the implications, and a frenzied sell-off ensues—often driven by sensationalized headlines. Then come the shrewd speculators, snapping up bargains at the expense of small investors who panic at the worst possible time.
Why History Keeps Repeating Itself
From the Dutch Tulip Mania in the 17th century to the crypto booms (and busts) of the 21st, speculative markets have always swung between euphoria and despair. The stock drop over DeepSeek is just another chapter in this centuries-old story. There’s a reason that market manipulation and misunderstanding repeat over time: human psychology is predictably volatile, swayed by fear, greed, and the allure of quick profits.

DeepSeek’s Innovations and Why They Matter
The story of DeepSeek begins with two extraordinary AI models—V3 and R1—whose technical achievements have sparked both awe and apprehension within the global tech community. At first glance, these breakthroughs in efficiency might suggest that the market for high-powered GPUs will contract. After all, if you can train a cutting-edge language model with fewer GPUs, why buy more of them? But dig a little deeper, and a very different picture emerges—one where the innovations powering V3 and R1 actually pave the way for bigger, more complex AI systems that demand more GPUs overall. Here’s a closer look at why these models are turning heads, and how their very design underscores the ongoing importance of graphics processing units in AI.
1. V3: A Masterclass in Efficiency
When DeepSeek unveiled V3, its most eye-catching claim was that this massive 671-billion-parameter model had been trained on a relatively modest cluster of 2,048 GPUs. In the world of AI, that’s akin to saying you built a skyscraper with half the steel and half the workforce typically required. The key lies in several underlying techniques:
Mixture of Experts (MoE)
How It Works: Instead of treating a single, monolithic neural network as the “know-it-all” for every query, DeepSeek’s architecture divides the workload among specialized “experts.” Each expert focuses on a certain subset of tasks—like mathematical reasoning, language understanding, or code generation—so not all parts of the model fire up for every token predicted.
Why It Matters: By activating only the subset of parameters relevant to each query, DeepSeek effectively lowers the per-token compute cost. In other words, training (or using) a single token of V3 might require only a fraction of the total model capacity. This design allows them to push the total parameter count higher without proportionally increasing resource usage.
Multi-head Latent Attention
The Bottleneck Problem: Large Language Models (LLMs) often get bogged down by bandwidth constraints—specifically, how much data can be moved between GPUs as they track context over thousands of tokens.
DeepSeek’s Twist: They compress key and value vectors (the pieces of data that store what the model “knows” about each token in the context) into more space-efficient representations. This reduces the memory overhead and network communication needed per token.
Practical Outcome: By easing these bottlenecks, V3 can handle long contexts more effectively, requiring fewer GPU hours to train on massive text corpora.
Quantization to 8-Bit
Less Precision, More Capacity: Traditional GPU-based AI training often uses 16-bit or even 32-bit floating-point precision. DeepSeek’s approach drops some layers to 8-bit precision where possible.
Double the Parameters, Same Memory: Halving the bits frees up GPU memory for more parameters, increasing the potential complexity and depth of the model without demanding more GPUs.
“Good Enough” Math: While it may sound like a big loss in accuracy, years of machine learning research show that many parts of a neural network function perfectly well—sometimes even better—with lower-precision arithmetic. DeepSeek capitalized on this to train a much larger model than would otherwise be feasible.
Meanwhile, in a wholly different domain of scientific curiosity, a newly updated paper titled the full list of 48 draft equations for “Super Dark Time” Theory revised in 5th version.
The full list of 48 draft equations for “Super Dark Time” Theory revised in 5th version.

Version 5 of the Super Dark Time paper has just been released. This new update clarifies how time behaves near massive objects, offers a fresh perspective on gravitational time dilation, and lays out a more rigorous framework for testing the theory’s predictions. The paper shows how time becomes thicker in the presence of mass, explaining the familiar s…
Authored by a researcher exploring the idea that variations in local time density—not just geometric curvature or graviton exchange—might underlie gravitational effects, this evolving theory proposes that mass effectively compresses time, causing clock rates to shift in ways reminiscent of gravitational wells. The changes include a new Outlook & Roadmap section to map future mathematical development.
And yet, just as breakthroughs in theoretical physics push us to rethink the cosmos, innovations in artificial intelligence—like DeepSeek’s surprisingly efficient models—have pushed stock markets and tech industries to revisit what “efficiency” truly means, especially in the context of corporate giants such as Nvidia.
2. R1: The “Reasoning” Model That Opens a New Frontier
If V3 was the appetizer, R1 served as the main course. This variant builds on V3’s architecture but adds crucial layers of reinforcement learning to tackle advanced reasoning tasks. The industry’s surprise wasn’t that R1 existed; models like OpenAI’s “o1” had already hinted at the promise of “thinking tokens.” Rather, what shocked people was just how close R1’s architecture seemed to be to V3—and how small the additional cost was to enable complex reasoning.
Thinking Tokens & Chain-of-Thought
What Are Thinking Tokens?: Instead of jumping straight from question to answer, R1 allows the model to lay out a series of “thought steps” in hidden form. These can be partially visible to the user, or even fully transparent, allowing researchers to see exactly how R1 arrives at its conclusions.
Open vs. Closed: OpenAI keeps “thinking tokens” for o1 largely hidden, citing safety and intellectual property concerns. DeepSeek, by contrast, opted for an “open reasoning” approach in R1, letting end-users peer into the model’s intermediate reasoning. This transparency has huge implications for debugging, auditing, and refining model outputs.
Reinforcement Learning (RL) Over Static Corpora
Self-Improvement Loop: Traditional model training relies on massive datasets with correct “labels.” R1, however, iterates on problems by attempting solutions, checking results, and adjusting its parameters based on successes or failures—a bit like how a chess engine learns from playing against itself.
Fewer Human Labels Needed: This drastically reduces the need for curated training data, which can be expensive and time-consuming to produce. R1’s success in “teaching itself” advanced math and logic tasks undercuts the assumption that you need armies of human annotators to guide AI reasoning.
Scaling Gains
Beyond Pretraining: As AI luminaries like Anthropic’s Dario Amodei have pointed out, the post-training or reasoning phase could soon dominate the demand for computational resources. That means once a model is pretrained, an even larger amount of compute might be poured into refining and extending its reasoning abilities.
A New Compute Paradigm: If R1 is any indication, the length and complexity of these reasoning sessions (and thus the number of tokens generated) will rise sharply as the model gets smarter. This all points to a hunger for more GPU hours—not less—over the model’s life cycle.
3. Efficiency as a Launchpad for Bigger AI, Not Smaller
The crux of the confusion around DeepSeek is the assumption that if you can do more with fewer GPUs, it automatically translates into less overall demand for those GPUs. But the AI sector has a long track record of devouring every efficiency gain—and then some—by scaling up ambitions:
The “Efficiency Paradox”: A concept seen across tech history. When computing becomes cheaper, we use more of it, not less. The classic example is data storage: as disks got cheaper, people started storing more data (photos, videos, high-resolution everything). The same logic applies to AI—lower cost per model means more models, bigger experiments, and a proliferation of use cases.
Room for Expansion: With methods like mixture of experts, quantization, and advanced attention schemes, researchers can imagine building models with trillions of parameters or specialized experts for every domain. Each new level of ambition drives demand for more GPUs or similarly specialized hardware.
Inference Load Explosion: Once an efficient model is developed, millions of users (or even billions, as AI integrates into consumer products) can hammer it with queries. If advanced reasoning is involved—like R1’s “thinking tokens”—the compute overhead grows with each extended back-and-forth query. Multiply that by a global user base, and the total GPU hours for inference alone can dwarf those used for training.
4. The U.S.–China Factor
The backdrop to DeepSeek’s rise is the ongoing tug-of-war between the United States and China over advanced semiconductor technology:
Export Controls: DeepSeek reportedly trained these models on the H800, a specialized version of Nvidia’s H100 GPU that was initially allowed for export to China. With further restrictions now in place, some commentators argue China is at a disadvantage for future models. But DeepSeek’s success shows that creative engineering can circumvent raw hardware constraints.
Global GPU Demand: Even if China’s access to top-tier GPUs is curtailed, markets in the U.S., Europe, and elsewhere will still be pushing the limits of AI. Nvidia’s revenue stream and market growth could shift geographically, but the total appetite for high-powered GPUs will likely remain insatiable.
Conclusion: Innovations That Fuel—Not Quell—GPU Demand
The technical breakthroughs in V3 and R1 are undeniably impressive. They’ve shown that one can squeeze extraordinary performance out of a smaller (or less advanced) GPU cluster through novel architectures, quantization tricks, and reinforcement learning. But far from rendering high-performance GPU hardware irrelevant, these achievements will likely accelerate the AI arms race.
As each new layer of efficiency is introduced, the overall scale of AI—both in terms of model size and usage volume—tends to expand. And in this expansion, Nvidia’s role is far from diminished; if anything, the future points toward more sophisticated GPU ecosystems and a rapidly diversifying set of AI workloads that will demand raw horsepower at an unprecedented scale.

The Nvidia Stock Crash—Myths vs. Reality
For a fleeting moment, DeepSeek was fingered as the primary culprit behind Nvidia’s sudden $600-billion market cap drop. Headlines read like prophecy: “Efficient AI Dooms GPU Giant,” and “Has DeepSeek Ushered in the End of the GPU Arms Race?” Yet even a cursory look under the hood shows that DeepSeek’s breakthroughs are more likely to increase demand for high-performance chips in the long term. So why did the market react so violently—and why does the “DeepSeek kills Nvidia” story still dominate popular discourse? The answers lie in a swirl of misunderstanding, geopolitical maneuvers, and old-fashioned market manipulation.
1. The Flawed Narrative: ‘Efficiency Equals Obsolescence’
At the heart of the crash chatter is a fundamental misunderstanding:
Mistaking Per-Model Efficiency for Overall Demand
One of the loudest claims is that because DeepSeek can train a massive model (V3 or R1) with fewer GPUs, it erodes the market for high-powered hardware. But as we explored on Page Two, every new efficiency gain historically expands AI adoption—more organizations can train bigger models at lower cost, which drives more total demand.Media Echo Chamber
In an era where social media posts can spark a stock sell-off within hours, the story that “DeepSeek’s wizardry replaces Nvidia” spread with little critical evaluation. Eye-catching headlines about a “GPU meltdown” got far more clicks than sober, technical explanations.AI Hype Fatigue
We’re also in a period where every AI news story is amplified. Investors have grown wary of repeated cycles of “revolutionary AI announcements” followed by short-lived mania. This fatigue made Nvidia’s drop easy to blame on a fresh face like DeepSeek, even though the actual market dynamics are more complex.
2. Hidden Forces: Trump’s Tariff Tangle
Those who dug deeper realized something else was happening in the background—a geopolitical spark that could have triggered the sell-off:
Tariff Leaks
Rumors began circulating that former President Donald Trump planned to slap new tariffs on Taiwanese-manufactured chips. This news, if credible, would directly impact TSMC, the linchpin of Nvidia’s supply chain. In such a scenario, Nvidia’s costs could rise, or production might slow—all legitimate reasons for a stock dip.Timing of the Announcement
What raised eyebrows was the timing: the market plunged days before Trump publicly confirmed his tariff plans, suggesting the possibility of an insider tip-off. Indeed, there was no second crash after the official announcement—an indication markets had “priced in” the bad news well in advance.Diversion Tactics
By the time the tariffs became a topic of mainstream coverage, the headlines had already swirled around DeepSeek as the main cause of the drop. Whether coincidental or deliberate, this narrative shift took attention off potential insider trading or the political drama driving investor fears.
